2つのdb.Modelの結合は Reference Property がないと遅い。
Reference Propertyを設定しても、ここに値(Key)が登録されていない場合、結合の際に以下のエラーとなる。(要エラー処理)
AttributeError: 'NoneType' object has no attribute 'entry_date'
1:1 の対応になるのであれば、大きな表形式にするのがやはり正しい。
ただし、1行ごとに fetch しながらの更新には時間がかかる。
200レコード程度の処理に15分かかった。(Windows による開発環境にて)
後から Reference Property にしろ、実際に追加したいデータにしろ、更新処理によりつけ加えるのには非常に時間がかかる。これは覚悟しておく必要がある。
from datetime import *
import datetime
from google.appengine.ext import db
class Stock(db.Model):
nikkei_ave = db.FloatProperty()
entry_date = db.DateTimeProperty()
modified = db.DateTimeProperty(auto_now=True)
usd_jpy = db.FloatProperty()
class Kawase(db.Model):
author = db.UserProperty()
usd_jpy = db.FloatProperty()
entry_date = db.DateTimeProperty()
modified = db.DateTimeProperty(auto_now=True)
stock = db.ReferenceProperty(Stock)
start_time = datetime.datetime.today()
e1 = datetime.datetime.strptime( "2003-08-01" ,'%Y-%m-%d')
e2 = datetime.datetime.strptime( "2003-08-22" ,'%Y-%m-%d')
kawases = db.GqlQuery("SELECT * FROM Kawase where entry_date >=:1 and entry_date <:2 ", e1,e2 )
for kawase in kawases:
stocks = db.GqlQuery("select * from Stock where entry_date = :1", kawase.entry_date )
for stock in stocks:
kawase.stock = stock.key()
kawase.put()
end_time = datetime.datetime.today()
print end_time - start_time
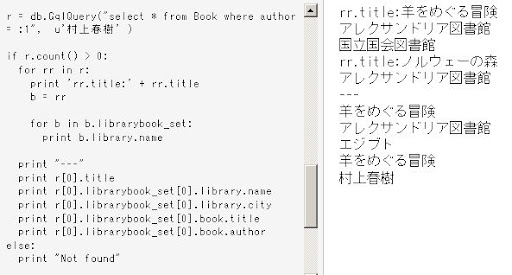
Kawase(db.Model) 側に Stock を参照するための Reference Property を追加し、ここに対応する Stock(db.Model) の Key を登録しておくと、 Kawase 側から簡単に Stock側の値を結合することができる。
Reference Property が抜けている(未登録)と
エラーになるので注意。
entity = db.GqlQuery("select * from Kawase")
for e in entity:
try:
print e.entry_date,e.usd_jpy, e.stock. entry_date, e.stock.nikkei_ave
except AttributeError:
print e.entry_date,e.usd_jpy, None,None
Kawase(db.Model) 側に Stock を参照するための Reference Property を追加し、ここに対応する Stock(db.Model) の Key を登録しておくと、 Kawase 側から簡単に Stock側の値を結合することができる。
Reference Property が抜けている(未登録)と
エラーになるので注意。
entity = db.GqlQuery("select * from Kawase")
for e in entity:
try:
print e.entry_date,e.usd_jpy, e.stock. entry_date, e.stock.nikkei_ave
except AttributeError:
print e.entry_date,e.usd_jpy, None,None
Stock 側からの結合は Stock 1 レコード(entity)対して、複数 Kawase レコードが対応する可能性があるので2段階のループになる。
entity = db.GqlQuery("select * from Stock limit 10")
for e in entity:
for k in e.kawase_set:
print e.entry_date,e.nikkei_ave, k.entry_date, k.usd_jpy
Stock と
Kawase を
entry_date で
join するため、Kawase 側に ReferenceProperty を作成した。Master-Detail でいうと Stock が Master側になるわけだが、これからDetail側を参照するために自動的に
kawase_set という擬似的なものが作成される。
確かにこれを
back-references と呼ぶのは仕組みがわかってくると、適切なように思える。
また、
back-references は遅いので注意。
上記の10件の join で 22秒もかかった。(SDKにて。 Kawase 1,935件、Stock 1,842件)
これは原則として Master側は1画面に1レコードとした使い方としないといけない。
Docs > Datastore API >
Entities and Models で
ReferenceProperty has another handy feature: back-references. When a model has a ReferenceProperty to another model, each referenced entity gets a property whose value is a Query that returns all of the entities of the first model that refer to it.と説明されている。